Bioschemas support to FAIR
FAIR on Training Material and Training Events Nettab 2018
Victoria Dominguez Del Angel @vic_bioinfo
Why caring about Training and event Training in life science scientists?
- Explosion of data analyze
- Thousand of possible tools and pipelines for specific analyses
- Find accurate learning path to improve skills and curriculum
Find training through Search Engines is not always easy
- Small labs, departments and organizations do not typically have as much traffic as larger institutions so are ranked lower in search results
- Harder to find advanced or niche topics. Training about common topics and introductory courses are more visible as they’re more popular
- Ending: Search engines are not optimal for finding training
FAIR Model
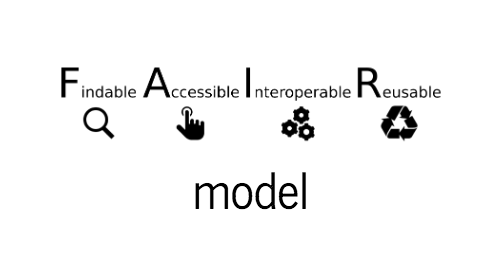
Findable
- TeSS Portal https://tess.elixir-europe.org
- Use metadata (YAML file, JSON and so on)
Accesible
Online: HTTP, HTTPS or REST Api (ex: wget, curl)
Interoperable
- Metadata description (YAML file, JSON-LD)
- Integration with ontologies as EDAM ONTOLOGY (link with other resources) DAG EDAM Browser
- Integration with FAIR resources (Dataset, tools and so on)
- Technical support for different platforms
Reusable
- Have a license ex: CC BY 4.0 license
- Provenance
- Reach Metadata
- Following community standards
Beyond FAIR
- Open development process on GitHub, GITLab & via Gitter
- Open education movement
- Open Data
TeSS Critical ressource for training in Bioinformatics
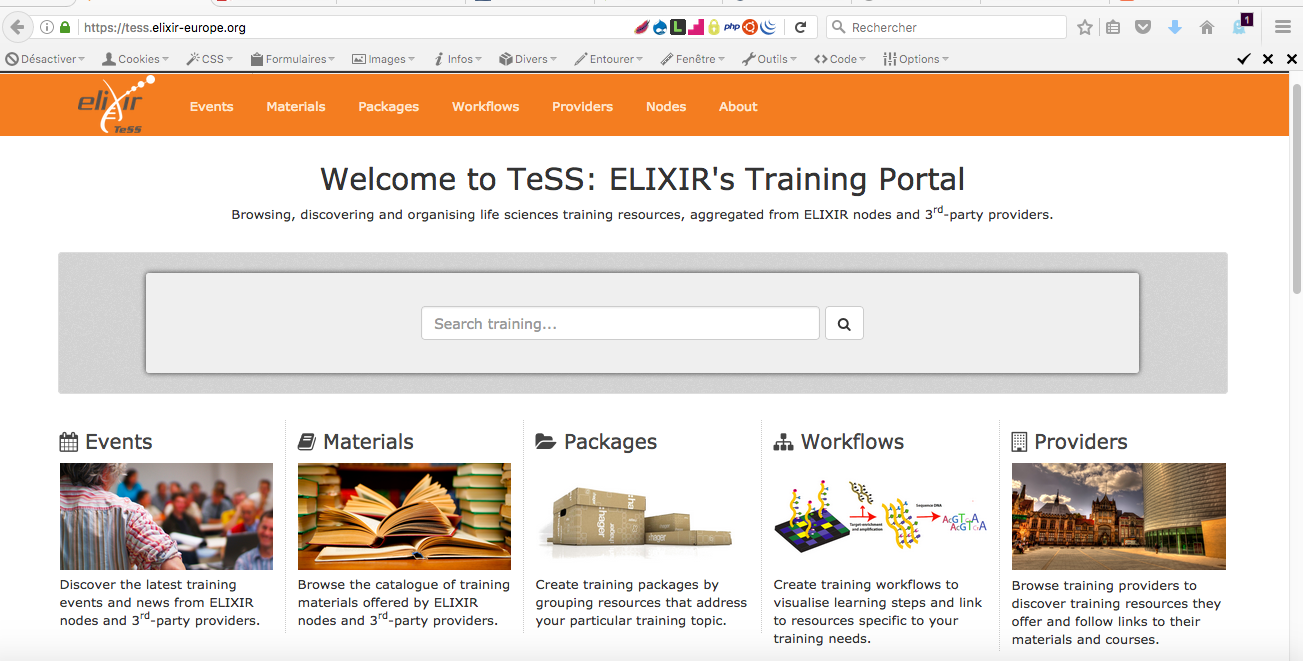 * TeSS Portal https://tess.elixir-europe.org
* TeSS Portal https://tess.elixir-europe.org
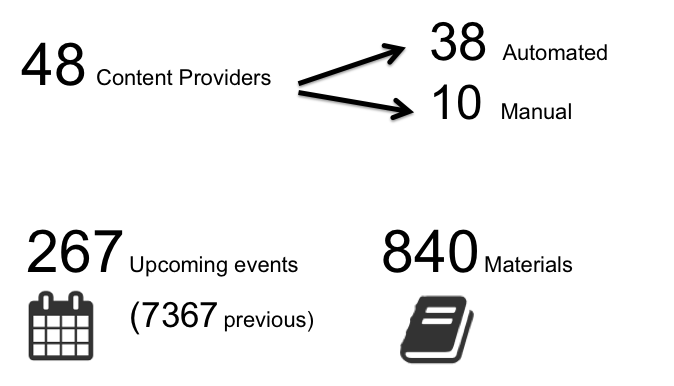
TeSS in numbers
Bioschemas on Goblet AGM 2017
- Goblet
- Having schema.org markup in training materials allows training registries to find your materials
- Event vocabulary: schema.org/Event; Event schema has many attributes, which not be important for training materials or courses
- Need to decide if event or course is better, as above groups use Event schema
- Bioschemas.org/TrainingEvent based on schema.org/Event (Topic: EDAM ontology)
- Bioschemas.org/TrainingMaterial based on schema.org/CreativeWork
Methodology for adopting a new profile
- Find and characterize Use cases
- TeSS and other training websites
- Perform a Cross Walk
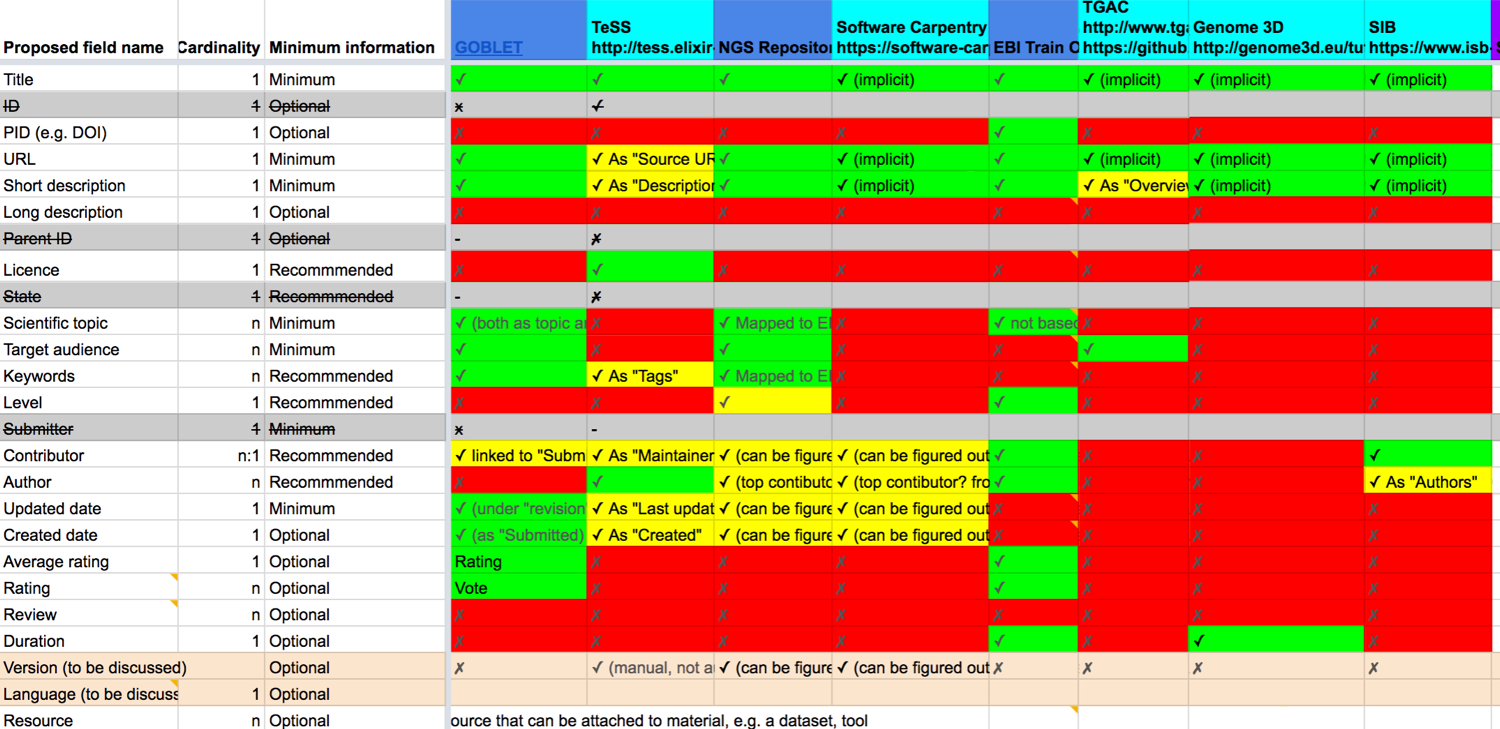
- Compared the metadata presented by 15 training providers
- Discussed and determined cardinality, minimum, controlled vocabs
- Keep discussion alive with Tasks and issues
- Forum for ongoing discussion via Github Issues
- Make Examples
- Show code examples to give adopters a sense of how to join
Bioschemas Cross Walk (Training Materials)
Adding Bioschemas to a website
- Map existing metadata to fields described by Bioschemas vocabulary
- Create a schema.org Expose those variables
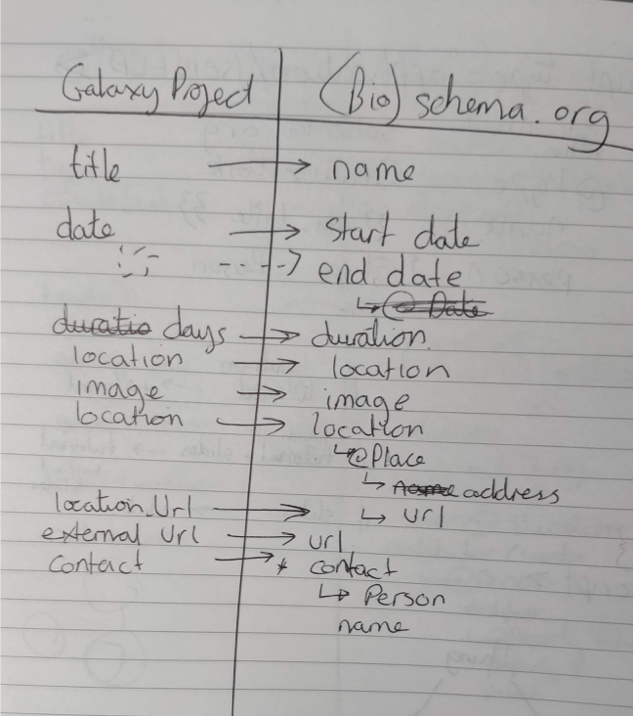
Mapping

Ongoing Work (TeSS and Goblet)
- We are currently working on an enhancement to schema.org/Event. Making Bioschemas for
- schema.org/Course
- schema.org/CourseInstance
- schema.org/Person
Special Thanks
- Goblet AGM 2017
- Niall Bernard
- Prof Terry Attwood
Hands-on

Wrap up
- Bioschemas is a community project which;
- Creates schema.org specifications for Life science resources : Proteins, Samples, Beacons, Tools, Training, Person, etc
- Create an enhanced interoperability layer to apply over schema.org
- Cardinality, Minimum information, controlled vocabularies: this constrains the content and format of the loose schema.org to allow automatic extraction
- Creates tools to make bioschemas easier to create, validate, and extract
Wrap up
- http://bioschemas.org/howtojoin/
- Join the W3C Bioschemas Community Group (detailed instructions below), this will also subscribe you to the mailing list
- Get involved in discussions on GitHub and Gitter
- Join our Slack workspace
What are you waiting for?
- come and join us !
- http://bioschemas.org